개인 회고
2023 경상남도 공공데이터 활용 아이디어 경진대회 프로젝트 회고
- -
728x90
동아리에서 진행한 마지막 프로젝트에 대한 회고록입니다.
1. 프로젝트 소개
의료소외지역 선정을 위한 회귀모형 개발 및 대시보드 제작
경상남도 창원 시 내 다양한 정보들을 기반으로 의료소외지수를 만들어 순위 별로 의료소외지역을 선정하겠다는 것을 목표로 프로젝트를 진행했습니다.
>>>>>>> 공모전 링크<<<<<<<<
진행기간
- 2023.06.19 ~2023.07.18
팀구성
- 최지혁 : 데이터 수집, EDA, 전처리, 아이디어 선정, 시각화, 회귀모델링, 발표자료 제작
- 박규영 : 데이터 수집, EDA, 전처리, 아이디어 선정, 대시보드 제작, 팀 리더(회의 진행 및 전반적인 과정 점검)
- 배진현 : 데이터 수집, EDA, 전처리, 아이디어 선정, 시각화, 최종 보고서 작성, 발표
- 김경동 : 데이터 수집, EDA, 전처리, 아이디어 선정, 시각화, 회귀모델링, 크롤링
사용 기술
- 데이터 전처리 : Pandas
- 시각화 : Matplotlib, Seaborn, Tableau, R
- 사용 툴: Python, R, Tableau
- 웹 구현: Tableau public
- 협업도구 : Github, Notion, Google Drive
프로젝트 개요
1. 아이디어 선정
경상남도 이슈 파악, 크롤링을 통한 트랜드 분석
2. 데이터 수집과 EDA 그리고 전처리
- 공공데이터포털과 환경빅데이터플랫폼, 행정안정부 등과 같이 데이터 플랫폼에서 각종 데이터 수집
- 데이터 시각화 및 이상치 처리, 다중공선성 제거, 데이터 정규화 및 로그 변환 등
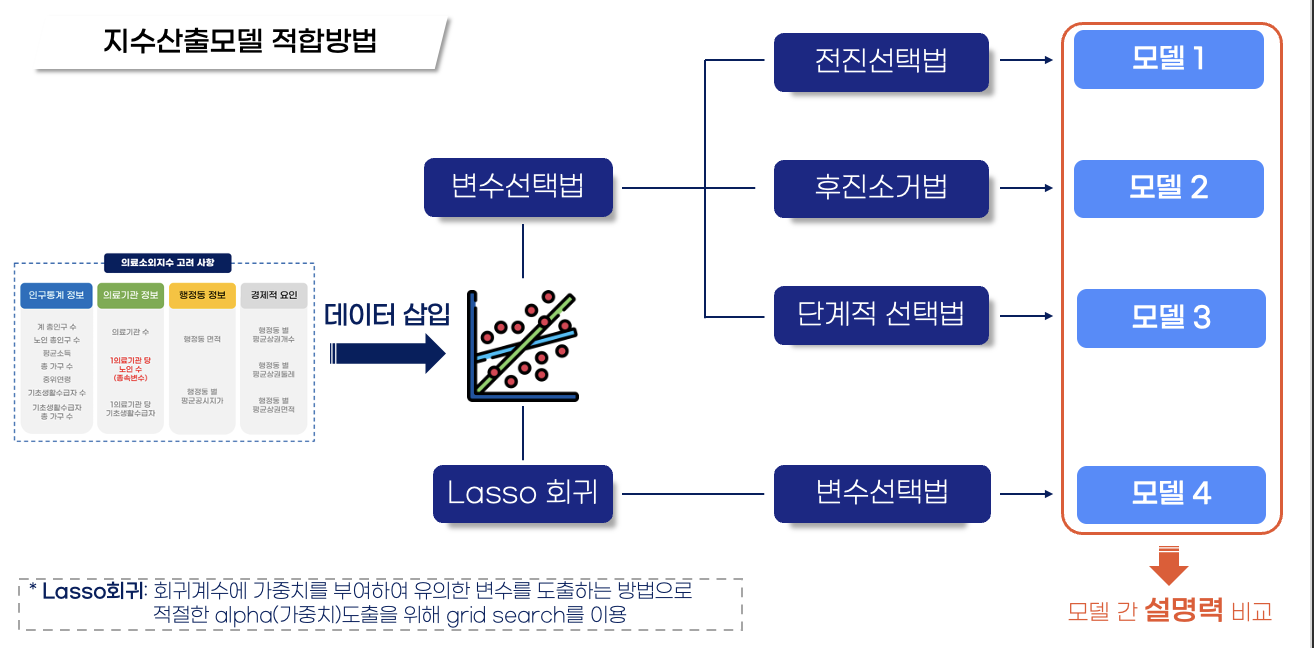
3. 회귀모델 제작
- 데이터에서 피쳐를 선정하기 위해 Lasso회귀, stepwise, 전진 및 후진 선택법 사용
- AIC 기준 최종 데이터 셋 선정
- adj R-squared 기준 최종 모델 선정
4. 대세보드 제작
- Tableau를 사용해 의료소외지역으로 선정된 지역과 그 수치를 일괄적으로 보여주는 대시보드 제작
- https://public.tableau.com/app/profile/.26001199/viz/_16889018879440/1_2
경상남도 공공데이터 활용 공모전 노인의료소외지역선정
경상남도 공공데이터 활용 공모전 노인의료소외지역선정
public.tableau.com
2. 프로젝트 진행과정
아이디어 선정
아이디어 진행과정은 브레인 스토밍으로 진행했다. 일단 각자 별의별 아이디어를 다 생각해 오고, 해당 아이디어가 적절한 데이터를 구할 수 있다면 후보군에 올려두었다.

각자 근래 경상남도 지역뉴스나 경상남도청 문제 해결 사례 등을 잘 조사하면서 아이디어를 발굴하고 실현가능한 아이디어를 추렸다.
위처럼 엘니뇨, 특수 쓰레기통 입지선정 등 기발한 아이디어가 다수 나왔으나 우리는 결국 굉장히 제한적인 '공공데이터'를 활용해야 헸기에 정작 정해진 아이디어는 뭔가 밋밋한(?) 맛이었다.
- 아이디어 1:의료소외지역 선정 및 선정지역별 대책 마련 (노인이 많은 곳, 관광지 등 특성)
- 노인비율, 지역별 가구수, 소득 수준, 병원 수, 응급실 수, 의료취약지수 등 이용
- 아이디어 2:심야약국 입지 선정
- 노인비율, 지역별 가구수, 소득 수준, 병원 수, 응급실 수, 의료취약지수 등 이용
최종적으로는 위 두 아이디어가 후보에 올랐는데 아이디어는 밋밋한 맛이더라도 공모전 평가 항목 중 독창성보다는 실현 가능성 부분이 10%나 더 비율을 차지했었기에 조금 더 질 좋은 데이터를 확보할 수 있는 주제로 방향을 잡았다.
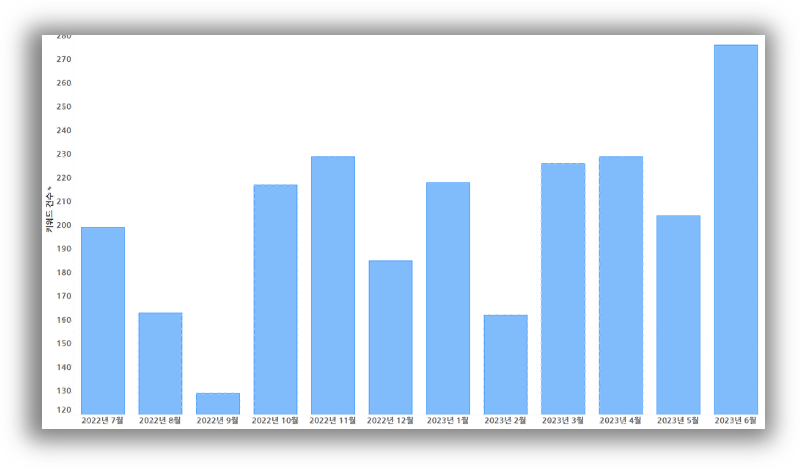

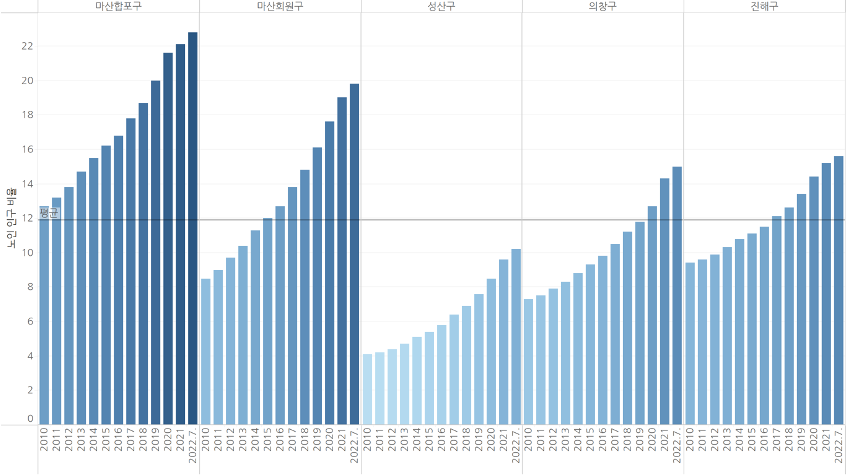
나중에 EDA 파트에서 나오겠지만 경상남도 뉴스를 기준으로 '의료'와 '병원'분야를 크롤링한 결과는 다음과 같다. 조금씩 편차는 보이지만 2022년 하반기부터 23년까지 의료 관련 키워드는 꾸준히 증가하는 추세이며 네이버 뉴스 기준 워드클라우드 결과 창원시, 병원, 사고 등 관련 키워드가 눈에 띄는 모습을 볼 수 있다. 또한 인구통계학적인 자료를 시각화한 것을 보면 연도 별로 노인 인구수 도 꾸준히 증가하는 것을 볼 수 있다.
따라서, 현재 꾸준히 의료, 병원 등에 관심도가 증가하고 사회적으로 많이 다뤄지는 분야이며 고령화 현상도 시시각각 진행 중이기 때문에 노인 의료공급을 미리 대비하자는 명목으로 최종적으로 다음과 같은 아이디어를 선정하였다.
"의료복지 효율화를 위한 창원시 노인 의료소외지역 선정"
데이터 수집
의료소외지역을 선정하기 위해서는 선정 기준이 있어야 한다. 우리는 의료소외지수를 직접 만들어 해당 지수가 높은 지역을 의료소외지역으로 선정하기로 했다.
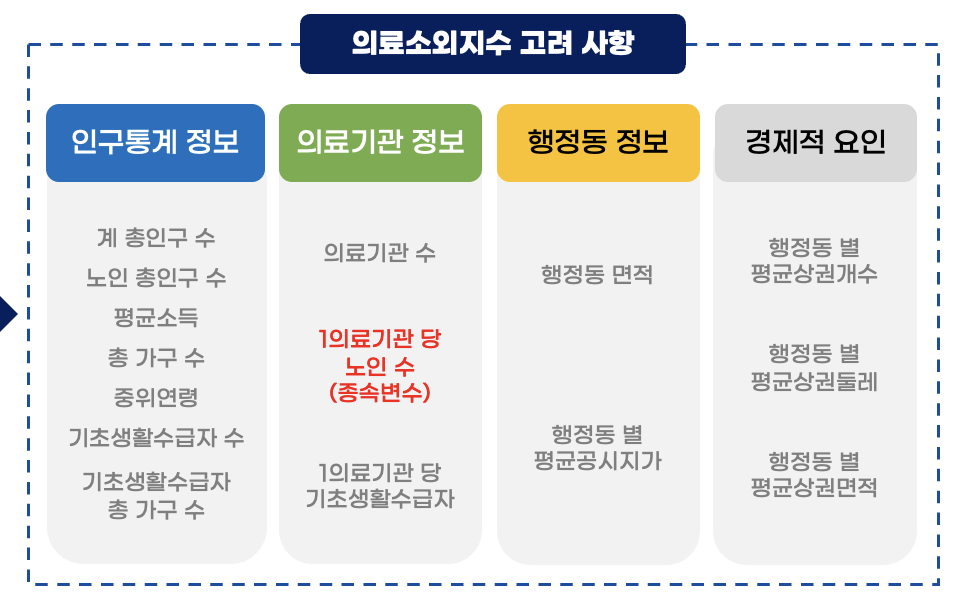
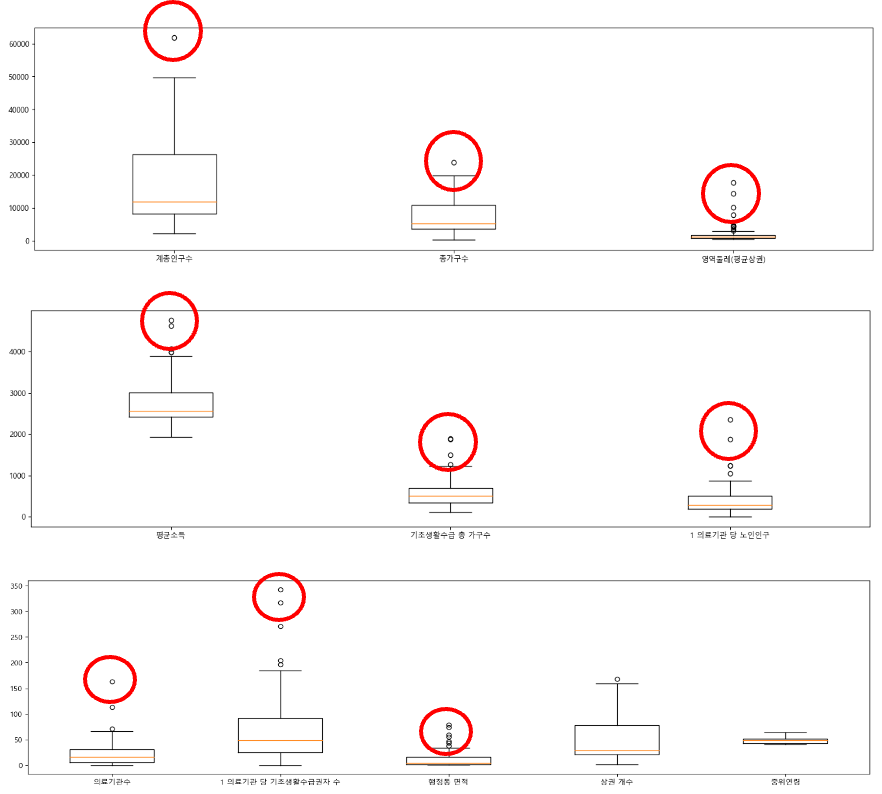
위와 같이 창원 시내 인구통계 정보, 의료기관 정보, 행정동 정보 등 다양한 정보들을 가져와 독립변수에 넣고 1 의료기관당 노인인구수(한 병원이 수용할 수 있는 노인 수)를 종속변수로 하여 회귀모델을 돌리기로 방향을 잡았다. 정말 공공데이터포털 사이트에서 조금이라도 관련이 있겠다 싶으면 데이터를 박박 긁어모았다. 특히 분석할 때 행정동 단위로 분석을 진행했기 때문에 간혹 가다 법정동 단위로 데이터가 나눠져 있다거나 자치구 수준에서만 집계된 데이터는 사용하지 못했다..ㅠㅠ
이상치와 다중공선성 등을 처리 후 전체 데이터를 정규화 겸 로그변환하여 밑에와 같은 방법으로 모델 선정을 했다.
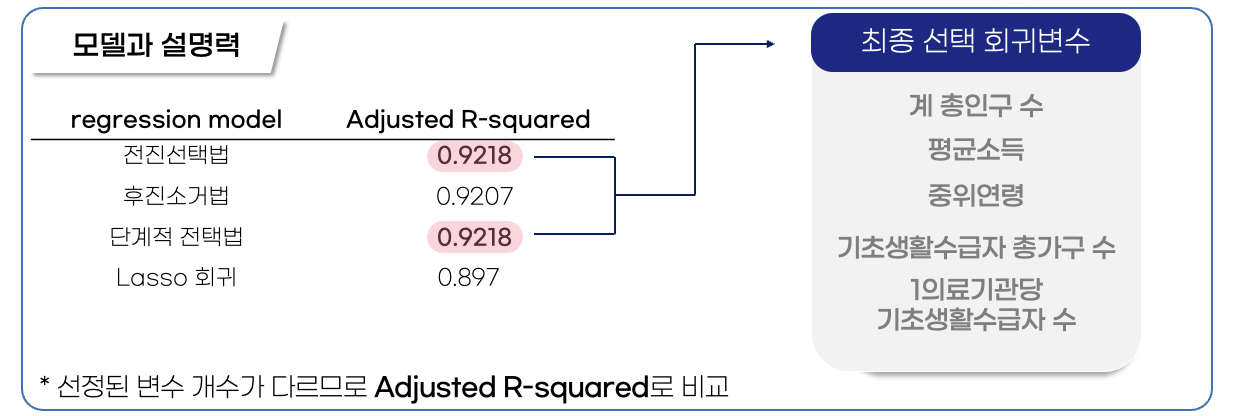
위처럼 전진선택법과 단계적 선택법의 결정계수가 똑같이 나왔는데 아니나 다를까 회귀변수도 똑같이 뽑혔다. 상당히 결정계수가 높아 과적합 가능성이 다분했지만 어차피 창원시 52개 행정동 별 데이터기 때문에 개수가 적어 그 정도는 예상했고 DB 구축을 하지 못해 시기별 데이터를 넣은 게 아닌 한 시점의 데이터를 넣었기 때문에 그 점은 조금 아쉽긴 했다. 어쨌든 최종 회귀식은 다음과 같이 나왔다. 사실 lasso 회귀식을 만들 때 gridsearch를 사용하여 알파값 최적화 작업을 진행했었는데 생각보다 좋은 결과를 보여주진 못해서 아쉬웠다.
Y = 0.01 ✕ 계 총인구수 – 0.15 ✕ 평균소득 -0.3 ✕ 기초생활수급 총가구수 +4.52 ✕ 1 의료기관 당 기초생활수급자 수 + 9.8 ✕ 중위연령
이제 기존의 행정동별 데이터를 그대로 삽입해 나온 Y값(의료소외지수)중 평균보다 큰 의료소외지수를 가진 지역들을 의료소외지수로 선정하여 데이터마다 바뀌는 대시보드를 Tableau를 통해 만들었다. 만드는 것은 우리 팀의 Tableau 에이스이신 박규영 선배가 전부 하셨는데 역시 기대를 저버리지 않으셨다.
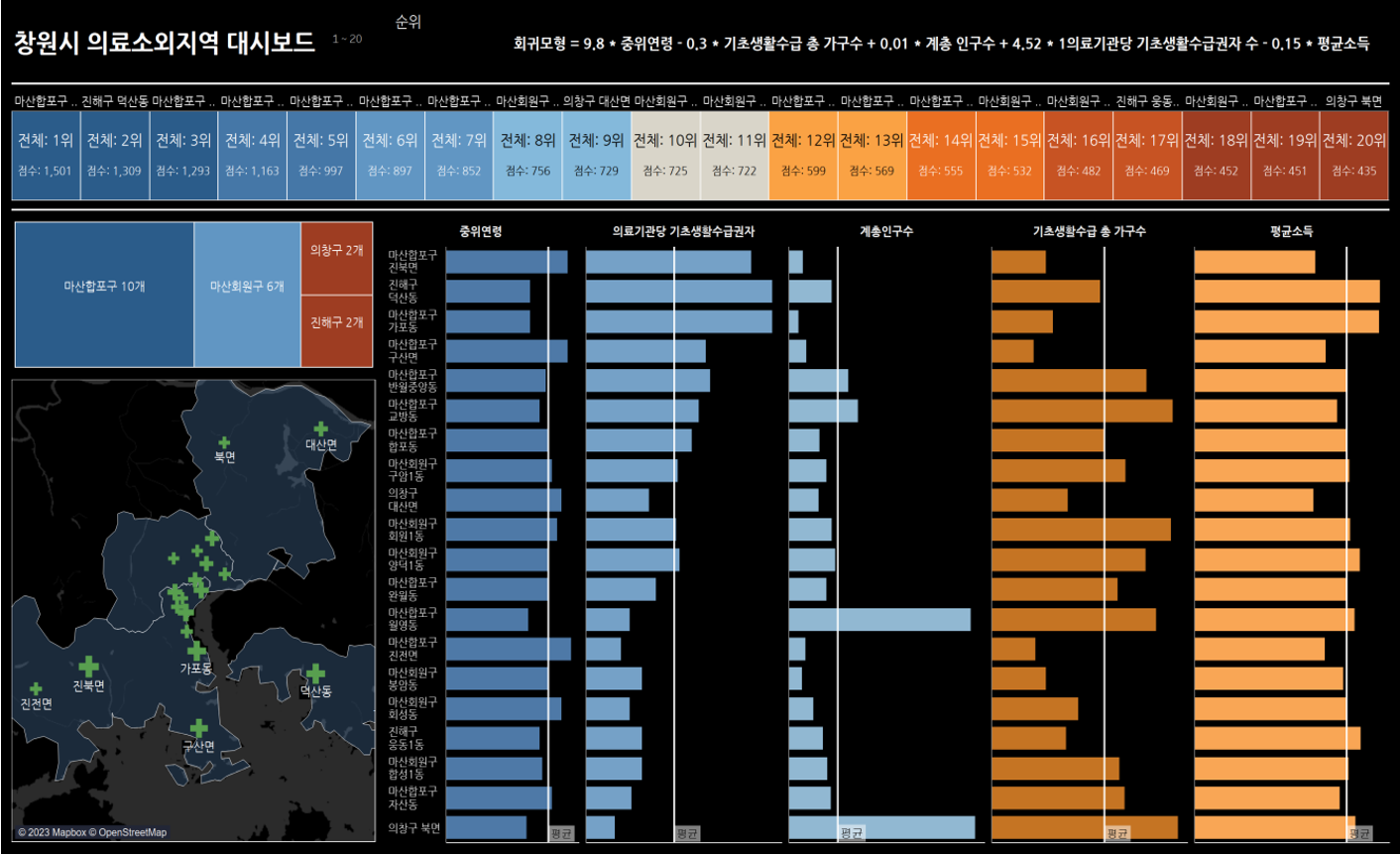
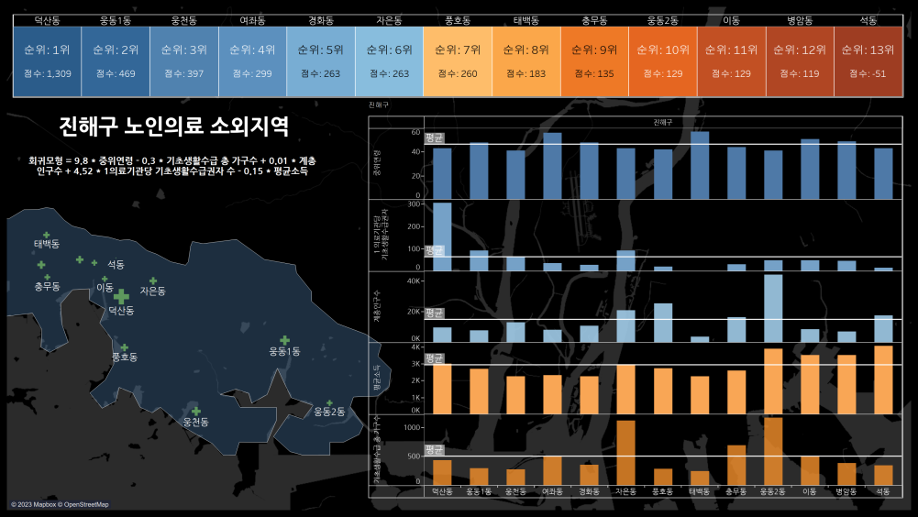
이렇게 대시보드를 제작하여 제작 후 확장가능성이나 편의성 영향력 등 다양한 아이디어를 더 추가하여 공모하였다.(자세한 내용은 github에 첨부)
1. 대시보드
그렇게 서류를 합격하고 본선에 진출하개 되었는데 경상남도청까지 직접 발걸음을 하게 되었다. 공모전 팀원들이 모두 수도권에 살았기 때문에 언제 내려가랴 걱정이 많았다. 더군다나 그 당시 폭우로 인해 KTX가 운행을 중단하여 팀원들이 장장 4시간가량 고속버스를 타고 창원까지 이동했다... 물론 나는 그 당시 패스트 캠퍼스 아르바이트가 있었기 때문에 본선 PT때 직접 가지는 못했지만(너무나 죄송스러웠어요ㅠㅠ) 마음만큼은..!!! 창원에 있었다. 발표결과는 나름 성공적이었고 질문이나 평가도 예상한 수준이었다. 분석이나 대시보드 측면에서는 좋은 점수를 받았으나 사업화나 아이디어면에서는 조금 아쉬운 평가였다. 살짝 혹평이 있어서 걱정이었는데 이게 웬일! 최우수상을 받아버렸다. 최우수상 팀은 나중에 행정안전부 통합 경진대회에 진출하게 된다는데 그것은 다른 포스팅에! 올리겠다.

잘했던 점
1. 학교에서 배운 지식 활용
대학교 강의에서 배운 내용을 활용한 분석이라 더 뜻깊었다. 회귀분석은 통계학과 전필과목으로 사실 학교에 다니면서 배운 내용으로 뭔가 의미 있는 일을 한다거나 하는 게 굉장히 어려운데 최우수상을 탔는 점 에서 의미 있었다고 본다.
2. 체계적인 데이터 수집
데이터를 수집할 때 기준을 잡고 수집한 것이 좀 컸던 것 같다. 단순히 "의료와 관련이 있을 것 같아!"하고 뽑은데 아닌 인구통계적 요인/경제적 요인/의료기관정보/행정동정보 이렇게 요인을 나누어 뽑은 점이 조금 더 완성도를 높이는데 기여하지 않았나 생각이 든다.
3. 대시보드 제작
대시보드를 만들어 시각적으로 포인트를 준 것이 수상에 큰 도움을 주었다고 생각한다. 단순히 분석을 한 것이 아닌 분석을 통해 대시보드라는 결과를 만들었기 때문에 수상을 할 수 있었다고 생각한다.
아쉬운 점
1. 팀원 간 역할 분담
사실 팀원 간 역할 분담이 그렇게 제대로 된 건 아니었다. EDA, 전처리, 모델링 각자 역할을 나누고 한 것이 아니라 다들 해 온다음 각자 발표하고 필요한 내용을 추리는 방식으로 진행이 되었기 때문에 불필요한 시간도 소모되었다고 생각한다. 다음 프로젝트를 하게 된다면 역할 군을 확실하게 나누고 싶다.
2. 데이터 베이스 구축
역시 DB 구축을 하지 않은 게 많이 아쉽다. 사실 의료소외지수를 제대로 산출하기 위해서는 해당 정보로는 부족하고 연도 혹은 월별로 주기적으로 집계된 데이터가 있어야 한다. DB구축을 통해 데이터를 시간대별로 가져올 수 있었다면 실시간 대시보드 제공이 가능했을 것이다.
3. 떨어지는 확장가능성
확장 가능성이 많이 떨어진다. 해당 회귀모형은 창원시에 국한된 회귀모형이다. 경상남도 다른 시에만 가도 분명 큰 오류가 날것이기 때문에 확장하려면 항상 새로운 데이터로 새로운 모델을 적합해야 한다. 때문에 다른 곳에 확장 적용하기 어려울 수 있다.
4. ML모델
ML모델과 같은 좀 더 고차원적인 분석 도구를 사용하지 않은데 조금 아쉽다. 우리가 한 분석은 회귀분석으로 사실 굉장히 고전적인 방법이다. 실제 업무나 연구에서도 추이를 보기 위해 간단하게 돌려보는 모델 정도로 사용되지 본격적인 분석에 있어서는 잘 쓰이지 않는다, 만약 데이터의 개수를 더 많이 확보할 수 있었다면 xgBoost나 LGBM, CatBoost와 같은 ML 모델을 사용하거나 스태킹을 쓴다든지 모델링 적으로 시간을 많이 투자해 봤을 것 같다.
5. 세세하지 못한 데이터의 분류
단순히 1 의료기관 당 병원 수로 나눈 것은 많이 아쉬웠다. 그 병원의 규모나 진료과목등은 거의 고려하지 않았기 때문에 해당 병원이 종합병원인지 아니면 작은 진료소인지 등의 정보도 나눠져 있었다면 더 자세하게 분석이 가능했을 것이다.
마무리하면서
사실 이번 프로젝트는 데이터 엔지니어링보다는 통계학부생들이 모여서 데이터 분석가의 역량을 발휘한 프로젝트라고 보는 게 맞는 것 같다. 하지만 내가 데이터 엔지니어링 공부를 하면서 나중에 언젠가 협업하게 될 대상은 분석가들이고 분석가들이 목적에 따라 어떤 데이터를 필요로 하는지 알 수 있다. 데이터 분석 동아리 DNA에서 진행한 마지막 프로젝트였기에 더 뜻깊었던 것 같다.
이번 프로젝트에 관한 github주소입니다.:)
https://github.com/weed0328/2023_Gyeongnam_Public_Data_Utilization_Idea_Competition
728x90
Contents
소중한 공감 감사합니다