Data Engineering
다양한 Web Crawling 및 Web Scraping 방법
- -
728x90
Crawling과 Scraping! 데이터 분야에 발을 담근 사람이라면 안 들어볼 수가 없는 영역이다. 사실 이 두 가지는 '원하는 데이터를 추출한다.'라는 공통 목적을 가진다. 때문에 기술적으로 같이 사용되기도 하고 일반적으로 혼용되지만 엄밀히 말하면 차이가 존재한다.
- Crawling: 웹상을 돌아다니며 방대한 양의 데이터를 수집한다. 웹 페이지의 링크를 타고 계속해서 탐색하여 html 페이지 및 링크 정보 등을 수집한다. - ex) 파이썬에 대해 알아보고 싶어 -> 파이썬 공식문서 전체 크롤링
- Scraping: 정확한 정보를 요구할 때 사용되기에 필요한 데이터만 수집한다. 흩어져있는 데이터를 다양한 패키지를 통해 자동으로 추출하여 전달할 수 있다. - ex) daily 환율가를 수집하고 싶어 -> 증권 페이지 스크래핑
위와 같은 차이가 있지만 사실 크게 구분할 필요는 없다. Web Crawling의 경우 모든 데이터를 모으기 때문에 정보의 확장성이 넓다는 장점이 있고, 서버의 자리를 많이 차지하여 리소스가 많이 들어간다는 단점이 있다. 반면에 Web Scraping의 경우, 적은 리소스를 들여 정확한 정보를 가져올 수 있지만, 그만큼 데이터의 한계가 있다. 보통 목적에 따라 섞어서 사용하기 때문에 이 정도 차이만 알면 크게 문제 되지 않는다.
데이터 엔지니어에게 위 두 가지는 사실 기본소양이라고 할 수 있다. 분석가나 ML 엔지니어 들은 보통 데이터를 제공받는다. 때문에 분석 방법론이나 변수처리, 모델 성능 등에 집중하면 된다.(물론 '데이터 잡부'들은 다 함.🥺) 하지만 데이터 엔지니어는 제공을 해줘야 하는 입장이고 Data Acquisition의 전반을 다루기 때문에 크롤링과 스크래핑을 반드시 다룰 줄 알아야 한다. 그럼 이제 어떤 식으로 크롤링을 하고 스크레핑을 하는지 알아보자
1. Crawling Recursive Way
재귀적으로 크롤링하는 방법이다. 하나의 웹페이지를 기준으로 안에 있는 링크들을 모두 수집해 나가기 때문에 재귀적으로 탐색해 나가는 것이 깔끔하다. Python3 버전의 공식 문서 페이지를 크롤링한다고 해보자.
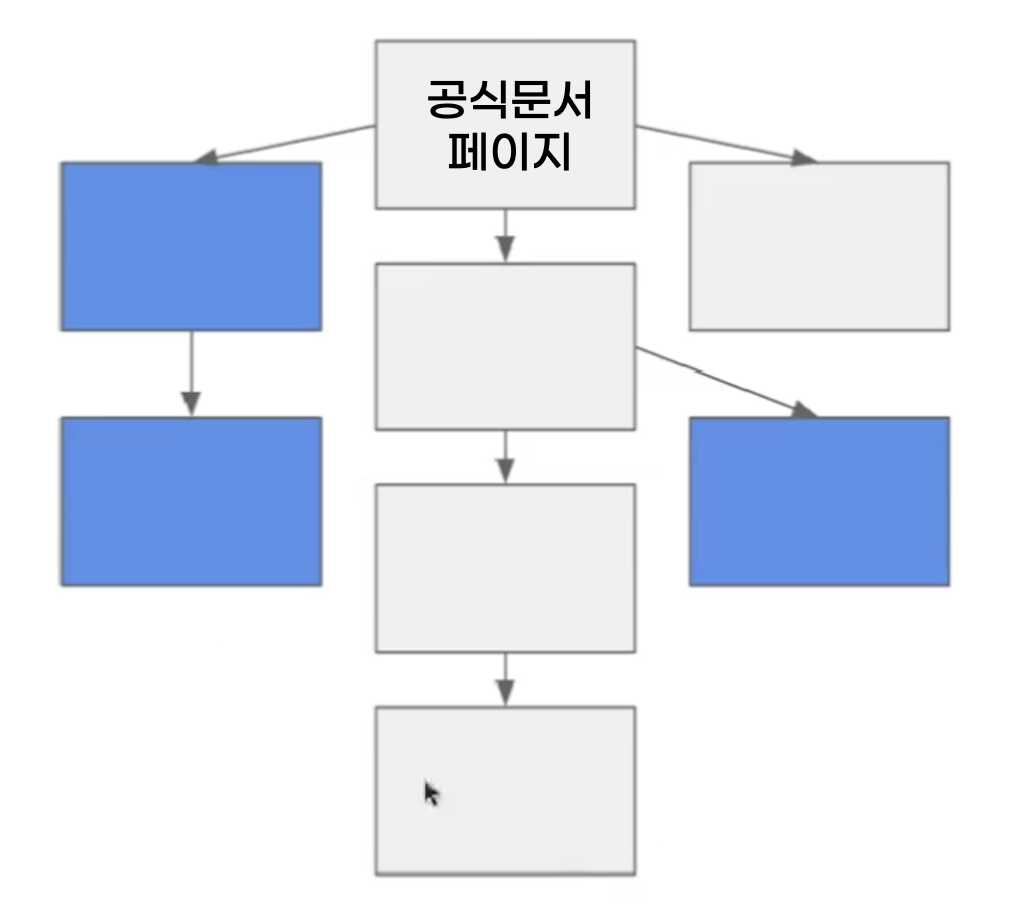
상위 디렉터리를 시작으로 링크를 타고 들어가며 각종 정보를 수집할 것이다. 먼저 재귀적 탐색을 이전에 작성해야 할 함수가 있다.
- HTML에서 링크와 CSS 파일을 추출하는 함수
- html에는 태그가 존재하는데 태그별로 들어 있는 정보가 상이하다. 우리는 link와 CSS 정보를 수집할 것이므로 링크 정보가 있는 <a> 태그와 외부 CSS 파일로 연결되는 <link> 태그를 찾아 추출하는 함수를 만들 것이다.
- 파일을 다운로드하는 함수
- 추출을 했으면 다운을 해야 한다. 다운 시 링크가 갈라질 경우 폴더도 생성해야 하며 오류 대비 코드도 작성해야 한다.
HTML에서 링크와 CSS 파일을 추출하는 함수
from urllib.parse import urljoin
from bs4 import BeautifulSoup
from urllib.request import *
from urllib.parse import *
from os import makedirs
import os.path, time, re
# 이미 처리한 파일을 추적하기 위한 딕셔너리
proc_files = {}
# HTML에서 링크와 CSS 파일을 추출하는 함수
def enum_links(html, base):
soup = BeautifulSoup(html, "html.parser")
links = soup.select("link[rel='stylesheet']")
links += soup.select("a[href]")
result = []
for a in links:
href = a.attrs['href']
url = urljoin(base, href)
result.append(url)
return result위 enum_links 함수는 주어진 html 문자 열과 기본 URL을 받아서 그 안에서 Beautiful Soup 라이브러리를 활용해 <link>와 <a> 태그를 찾아 관련된 URL을 추출한다. html에 있는 링크들은 전부 다 상대경로로 입력이 되어 있기에 절대경로로 바꿔주고자 urljoin 함수를 사용하였고 리스트에 저장한다.
파일을 다운로드하는 함수
# 파일을 다운로드하는 함수
def download_file(url):
o = urlparse(url)
savepath = "./" + o.netloc + o.path
if re.search(r"/$", savepath): # 폴더인지 여부를 확인하여 index.html 추가
savepath += "index.html"
savedir = os.path.dirname(savepath)
if not os.path.exists(savedir):
print("폴더 생성 =", savedir)
makedirs(savedir)
try:
print("다운로드 중 =", url)
urlretrieve(url, savepath)
time.sleep(1)
return savepath
except:
print("다운로드 오류 =", url)
return None이 함수는 주어진 URL에서 파일을 다운로드하고, 저장경로를 반환한다. 파일은 현재 디렉터리 내에./<netloc><path>에 저장된다. 폴더 여부에 따라 인덱스가 추가되도록 만들어주었다.
재귀적 탐색함수
def analyze_html(url, root_url):
savepath = download_file(url)
if savepath is None: return
if savepath in proc_files: return
proc_files[savepath] = True
print("analyzed html = ", url)
html = open(savepath, "r", encoding = "utf-8").read()
links = enum_links(html, url)
for link_url in links:
if link_url.find(root_url) != 0:
if not re.search(r".css", link_url): continue
if re.search(r".(html|htm)$", link_url):
analyze_html(link_url, root_url)
continue
download_file(link_url)
if __name__ == "__main__":
url = "https://docs.python.org/3/library/"
analyze_html(url, url)이 함수는 main 함수로 주어진 URL에서 HTML을 다운로드하고 그 HTML의 링크들을 추출하여 재귀적으로 다운로드한다. 이미 처리한 링크나 파일이 있을 경우 중복이 있어 리소스가 너무 많이 소모될 수 있기에 그것들은 proc_files = {}에 넣어두고 겹치면 생략하는 식으로 만들었다. 또한, 우리는 파이썬 3 공식 문서만 궁금한 것 이기 때문에 root 경로가 다른 링크들은 전부 제외하게끔 작성하였다. 얘들을 어 내부 링크가 library가 아닌 plugin일 경우 생략한다.
이런 식으로 크롤링을 진행하게 되면 우리가 정한 루트 안의 관련된 대부분의 링크들을 모두 다운로드하고 분석의 기반을 다질 수 있다.
2. WEP api Scraping
외부 api를 활용해 원하는 데이터를 추출할 수 있다. api에도 종류가 있지만 이번에는 web api를 통해 받아오고자 한다. Web api는 보통 공공기관에서 정보를 가져올 때 쓰이는데 어떤 자원들을 필요로 하느냐에 따라 기준이 있고 그 기준에 맞추어 정보를 가져올 수 있다.
open weathermap이라는 날씨 정보 제공 사이트가 있다.
웹 api의 경우 json 형태로 기준을 안내해 주는데 아래 사진은 main에서 temp를 명시하여 온도 정보를 가져올 수 있다는 뜻이다.
상세한 정보는 위 사이트에서 확인이 가능하다.

import requests
import json
# requests.get() == urllib.urlopen()
key = "본인의 API KEY"
cities = ["Seoul,KR", "Tokyo,JP", "Manchester"]
api = "https://api.openweathermap.org/data/2.5/weather?q={name}&appid={key}"
for name in cities:
url = api.format(name=name, key=key)
res = requests.get(url)
data = json.loads(res.text)
print("+ CITY = ", data["name"])
print("| WEATHER =", data["weather"][0]["description"])
print("| MIN TEMP =", round(data["main"]['temp_min'] - 273, 1)) # 켈빈온도 섭씨로 변환
print("| MIN TEMP =", round(data["main"]['temp_max'] - 273, 1))
print("| HUMIDIDTY =", data["main"]['humidity'])
print("| PRESSURE =", data["main"]['pressure'])
print("| DEG =", data["wind"]['deg'])
print("| SPEED =", data["wind"]['speed'])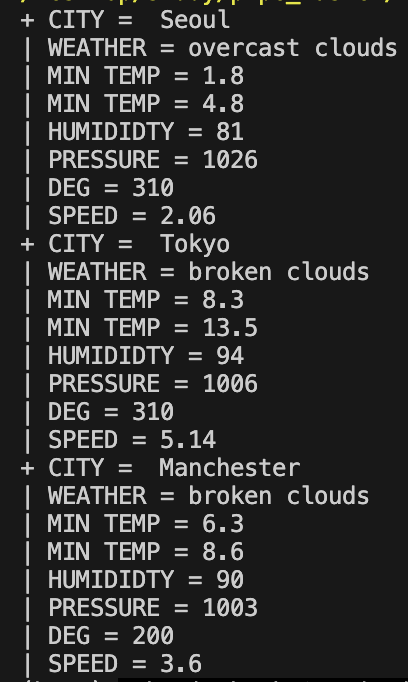
위처럼 원하는 도시의 정보를 api를 이용해 가져올 수 있다. 이렇게 간단하게 원하는 정보를 가져올 수 있다는 장점이 있기에 보통 학생 때 많이 사용한다.
3. RSS Scraping
RSS란 웹사이트 상의 콘텐츠들을 요약하고, 이를 서로 공유할 수 있도록 만든 '표준'이라고 정의되어 있다. 너무 어려우니 쉽게 얘기하면 간단한 게 우리가 웹사이트에 방문하지 않고도 실시간으로 업데이트된 내용을 전달받을 수 있게 만들어진 구독이라고 생각하면 된다. 가장 대표적으로 우리나라 기상청에서 RSS를 제공하는데 우리나라 각 지역의 날씨를 코드만 돌리면 언제든지 확인 가능하다.
#!/usr/bin/bin/env python3
import requests
from bs4 import BeautifulSoup
def main():
url = "http://www.kma.go.kr/weather/forecast/mid-term-rss3.jsp"
res = requests.get(url)
soup = BeautifulSoup(res.text)
locations = soup.find_all("location")
for location in locations:
city = location.find("city").text
date = location.find("data").find("tmef").text
weather = location.find("data").find("wf").text
print(f"[ {date} ] {city} : {weather}")
if __name__ == "__main__":
main()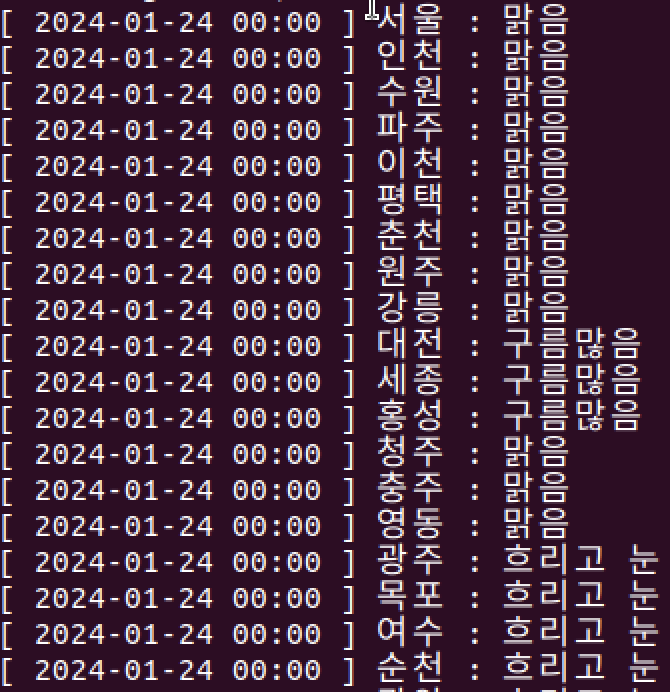
기상청 RSS 사이트에 들어가면 확장자가 jsp로 된 RSS 주소를 주는데 해당 주소를 불러와 지역변수를 뽑고 그 지역에 대한 현재 날씨 정보를 가져올 수 있다. 나는 도시 이름, 날짜, 현재 날씨 이렇게 3개를 format 하여 보기 좋게 출력하였다.
4. BeautifulSoup Scraping
사실 Scraping 하면 절대 빼놓을 수 없는 것이 바로 어여쁜 수프다. Scraping의 대명사라고도할 수 있고 정형 데이터뿐만 아니라 이미지와 같은 비정형 데이터도 수집가능하다. 아주 무궁무진하고 자주 사용하기 때문에 '이쁜 수프를 못쓴다' == 'Scraping을 할 줄 모른다'와 같은 소리도 들린다.
간단한 실습을 해보자 네이버 페이 증권 사이트에서 달러 환율을 가져올 것이다. 엄청 간단하다.
아래 사진에서 보는 것처럼 개발자 도구를 열고 원하는 정보가 기록된 html 부분에서 selector 정보를 복사해 select_one 함수에 인자로 넣어주면 된다. 이렇게만 하면 이런 사이트에서 원하는 정보만 쏙 하고 빼올 수 있다.
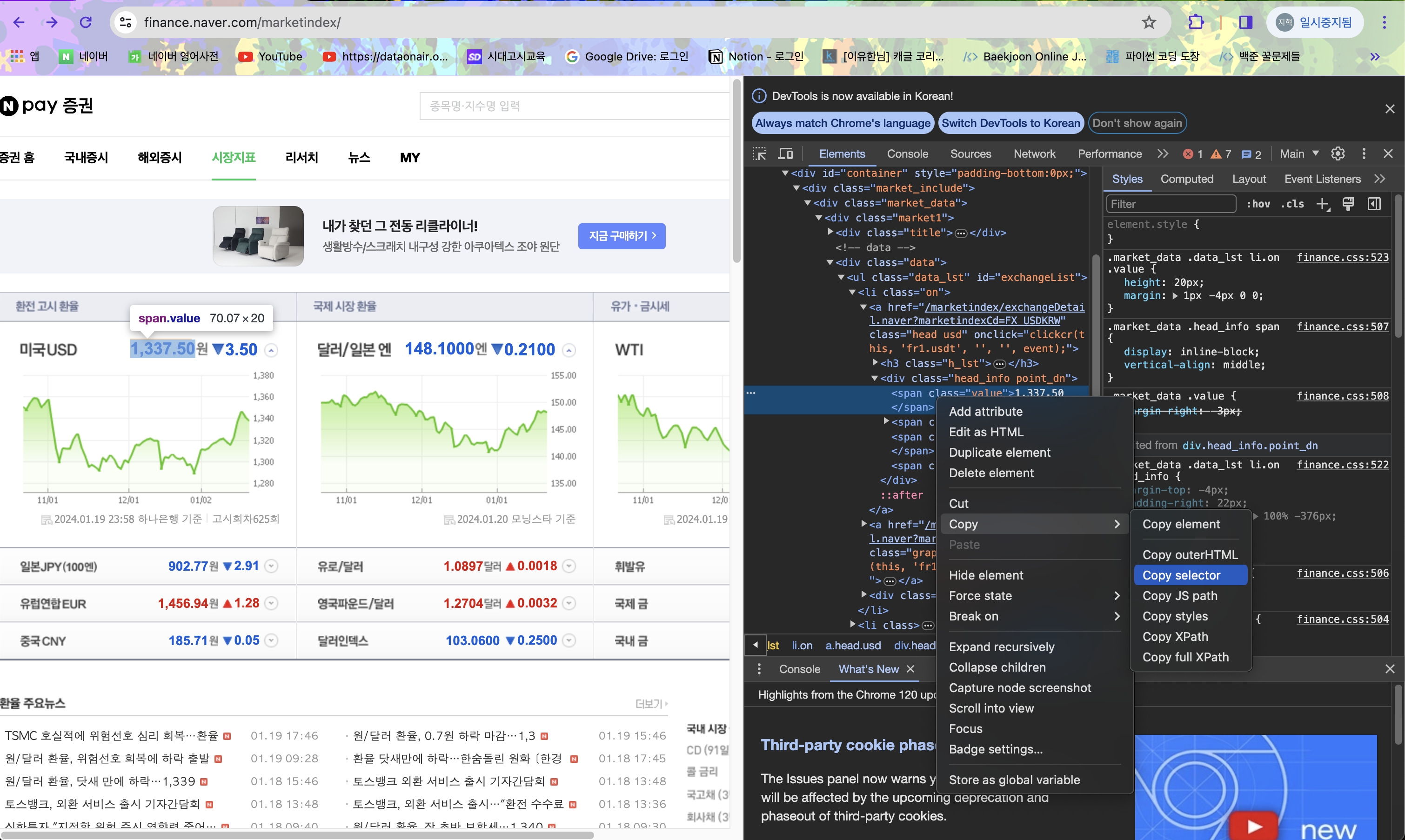
from bs4 import BeautifulSoup
import urllib.request as req
import datetime
url ="https://finance.naver.com/marketindex/"
now = datetime.datetime.now().strftime("%Y-%m-%d %H:%M:%S")
res = req.urlopen(url).read()
soup = BeautifulSoup(res, "html.parser")
currency = soup.select_one("#exchangeList > li.on > a.head.usd > div > span.value")
print("Date: " + now + " USD: " + currency.string)
이처럼 내가 설정한 포맷에 맞게 잘 가져온 것을 알 수 있다.
마무리
이처럼 다양한 크롤링 스크래핑 방법을 통해 데이터를 수집할 수 있다. 꾸준히 수집하고 싶을 경우 crontab을 이용하여 정기적인 실행이 가능하게 만들어도 되고 나중에는 airflow와 같은 워크플로 관리기술과 함께 파이프라인 작성에도 유용하게 사용할 수 있다. 사실 위에서 다룬 방법들은 굉장히 기초적인 방법이다. REST API를 통해서도 다룰 수 있는 데이터가 많기에 데이터 수집 목적과 종류에 따라 적절히 수집 방법을 선택하면 될 것 같다. 이제 수집 부분을 공부했으니 데이터를 적재할 수 있는 스토리지와 DB 등을 좀 더 자세히 다뤄 볼 예정이다.
728x90
'Data Engineering' 카테고리의 다른 글
| 뭐? Mongo DB가 가용성을 보장하지 않는다고? (0) | 2024.02.18 |
|---|
Contents
소중한 공감 감사합니다